In this article I present an I/O system that makes maximal use of the symmetry property that input and output has. I call this system Symmetrical I/O. I also compare this system with two alternative systems, and explain why a I chose Symmetrical I/O over the two alternatives. Adding I/O functionality to an arbitrary class using Symmetrical I/O is almost is almost perfectly symmetrical in the case that the procedure in the case of a input error is to exit the program with a suitable error message describing the nature of the error. The more general case where the program does not necessarily exit on errors is only slightly more complicated.
Information documenting how to use the standard I/O libraries is hard to find. At my present level of understanding, Symmetrical I/O is superior for meeting my own programming needs than the standard library.
|
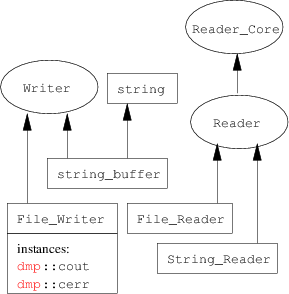
Adding I/O functionality to an arbitrary class X requires the user to add two new functions: operator << for output, and operator >> for input that behaves like a constructor.
Writer& operator <<() (Writer& w, const X& x); // for output Reader& operator >>() (Reader& r, X& x); // for input |
Here is a sample class with I/O functionality added:
class X { private: int a; double b; string c; public: X() { a = 0; b = 0; c = ""; } X(int a, double b, string c) { this->a = a; this->b = b; this->c = c; } friend Writer& operator << (Writer& w, const X& x) { ASSERT(&w != null); // Check for null reference ASSERT(&x != null); // Check for null reference w << "(X " << x.a << ' ' << x.b << ' ' << x.c << ')'; return w; } friend Reader& operator >> (Reader& r, X& x) { ASSERT(&r != null); // Check for null reference ASSERT(&x != null); // Check for null reference r >> '(' >> "X" >> x.a >> x.b >> x.c >> ')'; return r; } // ALTERNATIVE I/O SYSTEM: // X(Reader& r) // { // r >> '(' >> "X" >> a >> b >> c >> ')'; // } }; |
There is a minor flaw in the symmetry in the above code. In the output operation, whitespace must be added between all outputs except '(', ')' and the quote character ' so that when the output is later read as input, the parser is able to distinguish the tokens.
Another flaw is the subtle difference between reading const char&'s and reading const char*'s. In the output operation, outputting the const char& 'x' is identical to outputting the const char* "x". In the input operation a different function will be called depend on the type. Example:
r >> '('; // calls operator >> (Reader& r, const char& ch) r >> "abc"; // calls operator >> (Reader& r, const char* s) |
The former should be used exclusively for skipping over '(', ')' and the quote character ' and the latter should be used for skipping over literal const char* identifiers. It is vital that the const char* argument to operator >> (Reader& r, const char* s) contains no whitespace, '(', ')' or quote ' characters or else the parser will fail, giving an error message and exiting.
More generally outputting literal string identifiers with one or more spaces , '(', ')' or quote ' characters in them will confuse the parser when they are read back in. A multi-space literal string identifier will be read back in as multiple no spaced literal string identifiers. Brackets or quotes outputted as part of strings will be read back in as single character tokens. If your strings have spaces, brackets or quotes in them then quoted strings should be used for output and input. Example of quoted string output:
w << quoted(s); |
where w is a Writer&. The function quoted puts the string inside "double quotes" and quotes any quotes inside the string as well as certain non-printable characters. Example of quoted string input:
s = r.gulp_quoted_string(); |
where r is a Reader&. The method gulp_quoted_string decodes a string encoded using the function quoted.
Here is the main function that illustrates how to use the above I/O methods to read from and write to files and to write to the standard output stream. Note that cout has been defined specially as an instance of a subclass of Writer for use with my I/O library. Output to cout can be interspersed with output to std::cout, the standard C++ output stream or output to stout, the standard C output stream.
int main() { string filename = "output.el"; { X x(1,2.2,"cat"); File_Writer w(filename); w << ";; This is a data file\n"; w << x; } // ALTERNATIVE I/O SYSTEM: // { // File_Reader r(filename); // X x(r); // cout << "x=" << x << '\n'; // } { File_Reader r(filename); X x; r >> x; cout << "x=" << x << '\n'; } return EXIT_SUCCESS; } |
In the above code the extension ".el" stands for Emacs Lisp. The reason for the naming is that the output file format is largely compatible with Emacs Lisp. In particular, Lisp comments starting with ; to the end of line are skipped over by the Reader class. Here is the contents of the output file "output.el":
;; This is a data file (X 1 2.2 cat) |
One feature that my parser has over Emacs Lisp is the capability to read C/C++ style hexadecimal numbers. For example, outputting the string 0xffff is read back in as 65535, the decimal value of 0xffff.
The downside of my chosen approach is that the X objects must be created via a call to X() which takes no arguments, so no information from the input stream is available for the construction process. Only later inside the function operator >> (Reader& r, X&) can the X objects be created using information from the input stream.
An alternative to the Symmetrical I/O approach is to add stream input functionality by adding a constructor X(Reader& r) for inputing new objects, for each class X. The constructor approach fails for the built-in types bool, char, int, float and double because there is no way of defining a constructor for these types. Because built-in types cannot use the constructor approach, it is more elegant to use Symmetrical I/O for all types.
A second alternative is for every class X for which stream input is desired to have one the following functions defined:
X* read_object(const X& unused, Reader& r) |
The name of the function is arbitrary as long as it is evenly applied but the arguments to the function are not arbitrary. The arguments unused is a reference rather than a pointer so that anonymous temporary variable may be passed in to it.
The argument unused should be ignored by the implementor of each read_object method. It is only needed so that function name overloading calls the appropriate read_object method for each type. The second argument r represents the input stream and is used by the implementor of each read_object method to construct an object of the required type and return it via the return value of the function.
The read_object approach is not as elegant as the Symmetrical I/O approach so I don't use it.
Two convenience methods are provided for dynamically inspecting the contents of the input stream, and one method for skipping over tokens:
bool looking_at(char ch); bool looking_at(string s); void next_token(); |
Example of their usage:
while (!r.looking_at(')')) { // Process input stream... } |
if (r.looking_at("Foo")) { r.next_token(); // Skip over "Foo" identifier[,] same result as r >> "Foo" // Process input stream... } |
Here are some Reader methods that dynamically inspect the type of the current token:
bool currently_char() bool currently_int() bool currently_double() bool currently_identifier() bool currently_string() bool currently_eof() |
These methods give the parsing routines more intelligence by given them the ability to fail to read the intended type by doing something other than the default behaviour of exiting on errors. Consider the following code listing that illustrates the use of currently_* methods:
#include "io.hh" int main() { string file_name = "output.el"; { File_Writer w(file_name); // WRITE TO FILE: *** checkpoint 1 for (int i=0; i<100; i++) { int rnd = rand() % 8; ASSERT(rnd >= 0); ASSERT(rnd <= 7); switch (rnd) { case 0: w << '('; // output '(' char break; case 1: w << ')'; // output ')' char break; case 2: w << 123456; // output positive int break; case 3: w << -123456; // output negative int break; case 4: w << 123.456; // output positive double break; case 5: w << -123.456; // output negative double break; case 6: w << "apple"; // output identifier break; case 7: w << quoted("I am a string!"); // output quoted string break; default: cerr << "Not possible\n"; ASSERT(false); } w << ' '; // output whitespace between tokens } } { File_Reader r(file_name); // READ FROM FILE: *** checkpoint 2 while (!r.currently_eof()) { char read_char; int read_int; double read_double; string read_identifier; string read_string; if (r.currently_char()) { r >> read_char; cout << "read_char=" << read_char << endl; } else if (r.currently_int()) { r >> read_int; cout << "read_int=" << read_int << endl; } else if (r.currently_double()) { r >> read_double; cout << "read_double=" << read_double << endl; } else if (r.currently_identifier()) { r >> read_identifier; cout << "read_identifier=" << read_identifier << endl; } else if (r.currently_string()) { read_string = r.gulp_quoted_string(); cout << "read_string=" << quoted(read_string) << endl; } else { cerr << "*** Not possible\n"; ASSERT(false); } } } exit(EXIT_SUCCESS); } |
Checkpoint 1 above illustrates the writing of random tokens to a disk file. Because the tokens are random, an intelligent parser is needed when they are read back in as input. Checkpoint 2 above illustrates how the currently_* methods can be used to create a suitably intelligent parser.
|
io.hh |
|
io.cc |
|
string.hh |
|
Source code: t-write-read.cc Output file: t-write-read.el |
|
Source code: t-write-read2.cc Output file: t-write-read2.el |
|
io.tar.gz |
| Back to Research Projects |
|
This page has the following hit count:
|
